![]()
2024 New Databricks-Machine-Learning-Associate Dumps - Real Databricks Exam Questions
Dependable Databricks-Machine-Learning-Associate Exam Dumps to Become Databricks Certified
Databricks Databricks-Machine-Learning-Associate Exam Syllabus Topics:
| Topic | Details |
|---|---|
| Topic 1 |
|
| Topic 2 |
|
| Topic 3 |
|
| Topic 4 |
|
NEW QUESTION # 25
A data scientist is developing a machine learning pipeline using AutoML on Databricks Machine Learning.
Which of the following steps will the data scientist need to perform outside of their AutoML experiment?
- A. Model evaluation
- B. Model tuning
- C. Model deployment
- D. Exploratory data analysis
Answer: D
Explanation:
AutoML platforms, such as the one available in Databricks Machine Learning, streamline various stages of the machine learning pipeline including feature engineering, model selection, hyperparameter tuning, and model evaluation. However, exploratory data analysis (EDA) is typically performed outside the AutoML process. EDA involves understanding the dataset, visualizing distributions, identifying anomalies, and gaining insights into data before feeding it into a machine learning pipeline. This step is crucial for ensuring that the data is clean and suitable for model training but is generally done manually by the data scientist.
Reference
Databricks documentation on AutoML: https://docs.databricks.com/applications/machine-learning/automl.html
NEW QUESTION # 26
Which of the following machine learning algorithms typically uses bagging?
- A. Gradient boosted trees
- B. K-means
- C. Random forest
- D. Linear regression
- E. Decision tree
Answer: C
Explanation:
Random Forest is a machine learning algorithm that typically uses bagging (Bootstrap Aggregating). Bagging involves training multiple models independently on different random subsets of the data and then combining their predictions. Random Forests consist of many decision trees trained on random subsets of the training data and features, and their predictions are averaged to improve accuracy and control overfitting. This method enhances model robustness and predictive performance.
Reference:
Ensemble Methods in Machine Learning (Understanding Bagging and Random Forests).
NEW QUESTION # 27
A data scientist has developed a linear regression model using Spark ML and computed the predictions in a Spark DataFrame preds_df with the following schema:
prediction DOUBLE
actual DOUBLE
Which of the following code blocks can be used to compute the root mean-squared-error of the model according to the data in preds_df and assign it to the rmse variable?
- A.

- B.

- C.

- D.

Answer: B
Explanation:
To compute the root mean-squared-error (RMSE) of a linear regression model using Spark ML, the RegressionEvaluator class is used. The RegressionEvaluator is specifically designed for regression tasks and can calculate various metrics, including RMSE, based on the columns containing predictions and actual values.
The correct code block to compute RMSE from the preds_df DataFrame is:
regression_evaluator = RegressionEvaluator( predictionCol="prediction", labelCol="actual", metricName="rmse" ) rmse = regression_evaluator.evaluate(preds_df) This code creates an instance of RegressionEvaluator, specifying the prediction and label columns, as well as the metric to be computed ("rmse"). It then evaluates the predictions in preds_df and assigns the resulting RMSE value to the rmse variable.
Options A and B incorrectly use BinaryClassificationEvaluator, which is not suitable for regression tasks. Option D also incorrectly uses BinaryClassificationEvaluator.
Reference:
PySpark ML Documentation
NEW QUESTION # 28
A data scientist wants to use Spark ML to impute missing values in their PySpark DataFrame features_df. They want to replace missing values in all numeric columns in features_df with each respective numeric column's median value.
They have developed the following code block to accomplish this task:
The code block is not accomplishing the task.
Which reasons describes why the code block is not accomplishing the imputation task?
- A. It does not impute both the training and test data sets.
- B. It does not fit the imputer on the data to create an ImputerModel.
- C. The fit method needs to be called instead of transform.
- D. The inputCols and outputCols need to be exactly the same.
Answer: B
Explanation:
In the provided code block, the Imputer object is created but not fitted on the data to generate an ImputerModel. The transform method is being called directly on the Imputer object, which does not yet contain the fitted median values needed for imputation. The correct approach is to fit the imputer on the dataset first.
Corrected code:
imputer = Imputer( strategy="median", inputCols=input_columns, outputCols=output_columns ) imputer_model = imputer.fit(features_df) # Fit the imputer to the data imputed_features_df = imputer_model.transform(features_df) # Transform the data using the fitted imputer Reference:
PySpark ML Documentation
NEW QUESTION # 29
A machine learning engineer has identified the best run from an MLflow Experiment. They have stored the run ID in the run_id variable and identified the logged model name as "model". They now want to register that model in the MLflow Model Registry with the name "best_model".
Which lines of code can they use to register the model associated with run_id to the MLflow Model Registry?
- A. mlflow.register_model(f"runs:/{run_id}/best_model", "model")
- B. millow.register_model(f"runs:/{run_id)/model")
- C. mlflow.register_model(run_id, "best_model")
- D. mlflow.register_model(f"runs:/{run_id}/model", "best_model")
Answer: D
Explanation:
To register a model that has been identified by a specific run_id in the MLflow Model Registry, the appropriate line of code is:
mlflow.register_model(f"runs:/{run_id}/model", "best_model")
This code correctly specifies the path to the model within the run (runs:/{run_id}/model) and registers it under the name "best_model" in the Model Registry. This allows the model to be tracked, managed, and transitioned through different stages (e.g., Staging, Production) within the MLflow ecosystem.
Reference
MLflow documentation on model registry: https://www.mlflow.org/docs/latest/model-registry.html#registering-a-model
NEW QUESTION # 30
A data scientist has written a data cleaning notebook that utilizes the pandas library, but their colleague has suggested that they refactor their notebook to scale with big data.
Which of the following approaches can the data scientist take to spend the least amount of time refactoring their notebook to scale with big data?
- A. They can refactor their notebook to use Spark SQL.
- B. They can refactor their notebook to use the PySpark DataFrame API.
- C. They can refactor their notebook to process the data in parallel.
- D. They can refactor their notebook to utilize the pandas API on Spark.
- E. They can refactor their notebook to use the Scala Dataset API.
Answer: D
Explanation:
The data scientist can refactor their notebook to utilize the pandas API on Spark (now known as pandas on Spark, formerly Koalas). This allows for the least amount of changes to the existing pandas-based code while scaling to handle big data using Spark's distributed computing capabilities. pandas on Spark provides a similar API to pandas, making the transition smoother and faster compared to completely rewriting the code to use PySpark DataFrame API, Scala Dataset API, or Spark SQL.
Reference:
Databricks documentation on pandas API on Spark (formerly Koalas).
NEW QUESTION # 31
Which of the following statements describes a Spark ML estimator?
- A. An estimator is an alqorithm which can be fit on a DataFrame to produce a Transformer
- B. An estimator is an evaluation tool to assess to the quality of a model
- C. An estimator chains multiple alqorithms toqether to specify an ML workflow
- D. An estimator is a trained ML model which turns a DataFrame with features into a DataFrame with predictions
- E. An estimator is a hyperparameter arid that can be used to train a model
Answer: A
Explanation:
In the context of Spark MLlib, an estimator refers to an algorithm which can be "fit" on a DataFrame to produce a model (referred to as a Transformer), which can then be used to transform one DataFrame into another, typically adding predictions or model scores. This is a fundamental concept in machine learning pipelines in Spark, where the workflow includes fitting estimators to data to produce transformers.
Reference
Spark MLlib Documentation: https://spark.apache.org/docs/latest/ml-pipeline.html#estimators
NEW QUESTION # 32
A data scientist is utilizing MLflow Autologging to automatically track their machine learning experiments. After completing a series of runs for the experiment experiment_id, the data scientist wants to identify the run_id of the run with the best root-mean-square error (RMSE).
Which of the following lines of code can be used to identify the run_id of the run with the best RMSE in experiment_id?
- A.

- B.

- C.

- D.

Answer: B
Explanation:
To find the run_id of the run with the best root-mean-square error (RMSE) in an MLflow experiment, the correct line of code to use is:
mlflow.search_runs( experiment_id, order_by=["metrics.rmse"] )["run_id"][0] This line of code searches the runs in the specified experiment, orders them by the RMSE metric in ascending order (the lower the RMSE, the better), and retrieves the run_id of the best-performing run. Option C correctly represents this logic.
Reference
MLflow documentation on tracking experiments: https://www.mlflow.org/docs/latest/python_api/mlflow.html#mlflow.search_runs
NEW QUESTION # 33
Which statement describes a Spark ML transformer?
- A. A transformer chains multiple algorithms together to transform an ML workflow
- B. A transformer is a hyperparameter grid that can be used to train a model
- C. A transformer is a learning algorithm that can use a DataFrame to train a model
- D. A transformer is an algorithm which can transform one DataFrame into another DataFrame
Answer: D
Explanation:
In Spark ML, a transformer is an algorithm that can transform one DataFrame into another DataFrame. It takes a DataFrame as input and produces a new DataFrame as output. This transformation can involve adding new columns, modifying existing ones, or applying feature transformations. Examples of transformers in Spark MLlib include feature transformers like StringIndexer, VectorAssembler, and StandardScaler.
Reference:
Databricks documentation on transformers: Transformers in Spark ML
NEW QUESTION # 34
A data scientist has developed a random forest regressor rfr and included it as the final stage in a Spark MLPipeline pipeline. They then set up a cross-validation process with pipeline as the estimator in the following code block:
Which of the following is a negative consequence of including pipeline as the estimator in the cross-validation process rather than rfr as the estimator?
- A. The process will have a longer runtime because all stages of pipeline need to be refit or retransformed with each mode
- B. The process will leak data from the training set to the test set during the evaluation phase
- C. The process will be unable to parallelize tuning due to the distributed nature of pipeline
- D. The process will leak data prep information from the validation sets to the training sets for each model
Answer: A
Explanation:
Including the entire pipeline as the estimator in the cross-validation process means that all stages of the pipeline, including data preprocessing steps like string indexing and vector assembling, will be refit or retransformed for each fold of the cross-validation. This results in a longer runtime because each fold requires re-execution of these preprocessing steps, which can be computationally expensive.
If only the random forest regressor (rfr) were included as the estimator, the preprocessing steps would be performed once, and only the model fitting would be repeated for each fold, significantly reducing the computational overhead.
Reference:
Databricks documentation on cross-validation: Cross Validation
NEW QUESTION # 35
A data scientist has developed a linear regression model using Spark ML and computed the predictions in a Spark DataFrame preds_df with the following schema:
prediction DOUBLE
actual DOUBLE
Which of the following code blocks can be used to compute the root mean-squared-error of the model according to the data in preds_df and assign it to the rmse variable?
- A.

- B.

- C.

- D.

Answer: B
Explanation:
The code block to compute the root mean-squared error (RMSE) for a linear regression model in Spark ML should use the RegressionEvaluator class with metricName set to "rmse". Given the schema of preds_df with columns prediction and actual, the correct evaluator setup will specify predictionCol="prediction" and labelCol="actual". Thus, the appropriate code block (Option C in your list) that uses RegressionEvaluator to compute the RMSE is the correct choice. This setup correctly measures the performance of the regression model using the predictions and actual outcomes from the DataFrame.
Reference:
Spark ML documentation (Using RegressionEvaluator to Compute RMSE).
NEW QUESTION # 36
A team is developing guidelines on when to use various evaluation metrics for classification problems. The team needs to provide input on when to use the F1 score over accuracy.
Which of the following suggestions should the team include in their guidelines?
- A. The F1 score should be utilized over accuracy when there is significant imbalance between positive and negative classes and avoiding false negatives is a priority.
- B. The F1 score should be utilized over accuracy when there are greater than two classes in the target variable.
- C. The F1 score should be utilized over accuracy when identifying true positives and true negatives are equally important to the business problem.
- D. The F1 score should be utilized over accuracy when the number of actual positive cases is identical to the number of actual negative cases.
Answer: A
Explanation:
The F1 score is the harmonic mean of precision and recall and is particularly useful in situations where there is a significant imbalance between positive and negative classes. When there is a class imbalance, accuracy can be misleading because a model can achieve high accuracy by simply predicting the majority class. The F1 score, however, provides a better measure of the test's accuracy in terms of both false positives and false negatives.
Specifically, the F1 score should be used over accuracy when:
There is a significant imbalance between positive and negative classes.
Avoiding false negatives is a priority, meaning recall (the ability to detect all positive instances) is crucial.
In this scenario, the F1 score balances both precision (the ability to avoid false positives) and recall, providing a more meaningful measure of a model's performance under these conditions.
Reference:
Databricks documentation on classification metrics: Classification Metrics
NEW QUESTION # 37
Which of the following tools can be used to parallelize the hyperparameter tuning process for single-node machine learning models using a Spark cluster?
- A. Autoscaling clusters
- B. MLflow Experiment Tracking
- C. Spark ML
- D. Autoscaling clusters
- E. Delta Lake
Answer: C
Explanation:
Spark ML (part of Apache Spark's MLlib) is designed to handle machine learning tasks across multiple nodes in a cluster, effectively parallelizing tasks like hyperparameter tuning. It supports various machine learning algorithms that can be optimized over a Spark cluster, making it suitable for parallelizing hyperparameter tuning for single-node machine learning models when they are adapted to run on Spark.
Reference
Apache Spark MLlib Guide: https://spark.apache.org/docs/latest/ml-guide.html Spark ML is a library within Apache Spark designed for scalable machine learning. It provides tools to handle large-scale machine learning tasks, including parallelizing the hyperparameter tuning process for single-node machine learning models using a Spark cluster. Here's a detailed explanation of how Spark ML can be used:
Hyperparameter Tuning with CrossValidator: Spark ML includes the CrossValidator and TrainValidationSplit classes, which are used for hyperparameter tuning. These classes can evaluate multiple sets of hyperparameters in parallel using a Spark cluster.
from pyspark.ml.tuning import CrossValidator, ParamGridBuilder
from pyspark.ml.evaluation import BinaryClassificationEvaluator
# Define the model
model = ...
# Create a parameter grid
paramGrid = ParamGridBuilder() \
.addGrid(model.hyperparam1, [value1, value2]) \
.addGrid(model.hyperparam2, [value3, value4]) \
.build()
# Define the evaluator
evaluator = BinaryClassificationEvaluator()
# Define the CrossValidator
crossval = CrossValidator(estimator=model,
estimatorParamMaps=paramGrid,
evaluator=evaluator,
numFolds=3)
Parallel Execution: Spark distributes the tasks of training models with different hyperparameters across the cluster's nodes. Each node processes a subset of the parameter grid, which allows multiple models to be trained simultaneously.
Scalability: Spark ML leverages the distributed computing capabilities of Spark. This allows for efficient processing of large datasets and training of models across many nodes, which speeds up the hyperparameter tuning process significantly compared to single-node computations.
Reference
Apache Spark MLlib Documentation
Hyperparameter Tuning in Spark ML
NEW QUESTION # 38
A data scientist wants to parallelize the training of trees in a gradient boosted tree to speed up the training process. A colleague suggests that parallelizing a boosted tree algorithm can be difficult.
Which of the following describes why?
- A. Gradient boosting calculates gradients in evaluation metrics using all cores which prevents parallelization.
- B. Gradient boosting is not a linear algebra-based algorithm which is required for parallelization
- C. Gradient boosting requires access to all data at once which cannot happen during parallelization.
- D. Gradient boosting is an iterative algorithm that requires information from the previous iteration to perform the next step.
Answer: D
Explanation:
Gradient boosting is fundamentally an iterative algorithm where each new tree is built based on the errors of the previous ones. This sequential dependency makes it difficult to parallelize the training of trees in gradient boosting, as each step relies on the results from the preceding step. Parallelization in this context would undermine the core methodology of the algorithm, which depends on sequentially improving the model's performance with each iteration.
Reference:
Machine Learning Algorithms (Challenges with Parallelizing Gradient Boosting).
Gradient boosting is an ensemble learning technique that builds models in a sequential manner. Each new model corrects the errors made by the previous ones. This sequential dependency means that each iteration requires the results of the previous iteration to make corrections. Here is a step-by-step explanation of why this makes parallelization challenging:
Sequential Nature: Gradient boosting builds one tree at a time. Each tree is trained to correct the residual errors of the previous trees. This requires the model to complete one iteration before starting the next.
Dependence on Previous Iterations: The gradient calculation at each step depends on the predictions made by the previous models. Therefore, the model must wait until the previous tree has been fully trained and evaluated before starting to train the next tree.
Difficulty in Parallelization: Because of this dependency, it is challenging to parallelize the training process. Unlike algorithms that process data independently in each step (e.g., random forests), gradient boosting cannot easily distribute the work across multiple processors or cores for simultaneous execution.
This iterative and dependent nature of the gradient boosting process makes it difficult to parallelize effectively.
Reference
Gradient Boosting Machine Learning Algorithm
Understanding Gradient Boosting Machines
NEW QUESTION # 39
A data scientist is performing hyperparameter tuning using an iterative optimization algorithm. Each evaluation of unique hyperparameter values is being trained on a single compute node. They are performing eight total evaluations across eight total compute nodes. While the accuracy of the model does vary over the eight evaluations, they notice there is no trend of improvement in the accuracy. The data scientist believes this is due to the parallelization of the tuning process.
Which change could the data scientist make to improve their model accuracy over the course of their tuning process?
- A. Change the number of compute nodes to be double or more than double the number of evaluations.
- B. Change the iterative optimization algorithm used to facilitate the tuning process.
- C. Change the number of compute nodes to be half or less than half of the number of evaluations.
- D. Change the number of compute nodes and the number of evaluations to be much larger but equal.
Answer: B
Explanation:
The lack of improvement in model accuracy across evaluations suggests that the optimization algorithm might not be effectively exploring the hyperparameter space. Iterative optimization algorithms like Tree-structured Parzen Estimators (TPE) or Bayesian Optimization can adapt based on previous evaluations, guiding the search towards more promising regions of the hyperparameter space.
Changing the optimization algorithm can lead to better utilization of the information gathered during each evaluation, potentially improving the overall accuracy.
Reference:
Hyperparameter Optimization with Hyperopt
NEW QUESTION # 40
A data scientist is developing a single-node machine learning model. They have a large number of model configurations to test as a part of their experiment. As a result, the model tuning process takes too long to complete. Which of the following approaches can be used to speed up the model tuning process?
- A. Implement MLflow Experiment Tracking
- B. Scale up with Spark ML
- C. Parallelize with Hyperopt
- D. Enable autoscaling clusters
Answer: C
Explanation:
To speed up the model tuning process when dealing with a large number of model configurations, parallelizing the hyperparameter search using Hyperopt is an effective approach. Hyperopt provides tools like SparkTrials which can run hyperparameter optimization in parallel across a Spark cluster.
Example:
from hyperopt import fmin, tpe, hp, SparkTrials search_space = { 'x': hp.uniform('x', 0, 1), 'y': hp.uniform('y', 0, 1) } def objective(params): return params['x'] ** 2 + params['y'] ** 2 spark_trials = SparkTrials(parallelism=4) best = fmin(fn=objective, space=search_space, algo=tpe.suggest, max_evals=100, trials=spark_trials) Reference:
Hyperopt Documentation
NEW QUESTION # 41
A data scientist is wanting to explore summary statistics for Spark DataFrame spark_df. The data scientist wants to see the count, mean, standard deviation, minimum, maximum, and interquartile range (IQR) for each numerical feature.
Which of the following lines of code can the data scientist run to accomplish the task?
- A. spark_df.stats()
- B. spark_df.toPandas()
- C. spark_df.printSchema()
- D. spark_df.summary ()
- E. spark_df.describe().head()
Answer: D
Explanation:
The summary() function in PySpark's DataFrame API provides descriptive statistics which include count, mean, standard deviation, min, max, and quantiles for numeric columns. Here are the steps on how it can be used:
Import PySpark: Ensure PySpark is installed and correctly configured in the Databricks environment.
Load Data: Load the data into a Spark DataFrame.
Apply Summary: Use spark_df.summary() to generate summary statistics.
View Results: The output from the summary() function includes the statistics specified in the query (count, mean, standard deviation, min, max, and potentially quartiles which approximate the interquartile range).
Reference
PySpark Documentation: https://spark.apache.org/docs/latest/api/python/reference/api/pyspark.sql.DataFrame.summary.html
NEW QUESTION # 42
A data scientist has been given an incomplete notebook from the data engineering team. The notebook uses a Spark DataFrame spark_df on which the data scientist needs to perform further feature engineering. Unfortunately, the data scientist has not yet learned the PySpark DataFrame API.
Which of the following blocks of code can the data scientist run to be able to use the pandas API on Spark?
- A. import pandas as pd
df = pd.DataFrame(spark_df) - B. import pyspark.pandas as ps
df = ps.DataFrame(spark_df) - C. spark_df.to_sql()
- D. import pyspark.pandas as ps
df = ps.to_pandas(spark_df) - E. spark_df.to_pandas()
Answer: B
Explanation:
To use the pandas API on Spark, which is designed to bridge the gap between the simplicity of pandas and the scalability of Spark, the correct approach involves importing the pyspark.pandas (recently renamed to pandas_api_on_spark) module and converting a Spark DataFrame to a pandas-on-Spark DataFrame using this API. The provided syntax correctly initializes a pandas-on-Spark DataFrame, allowing the data scientist to work with the familiar pandas-like API on large datasets managed by Spark.
Reference
Pandas API on Spark Documentation: https://spark.apache.org/docs/latest/api/python/user_guide/pandas_on_spark/index.html
NEW QUESTION # 43
A machine learning engineer is using the following code block to scale the inference of a single-node model on a Spark DataFrame with one million records: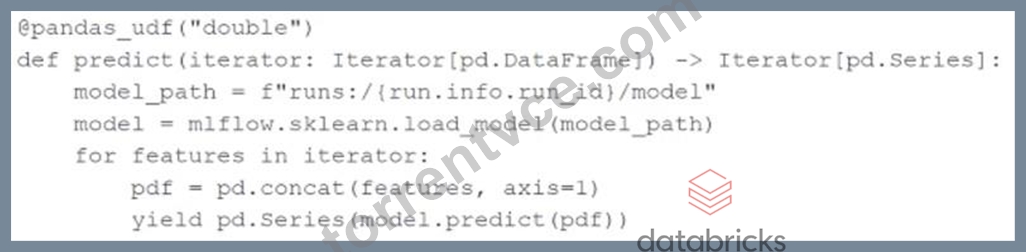
Assuming the default Spark configuration is in place, which of the following is a benefit of using an Iterator?
- A. The model will be limited to a single executor preventing the data from being distributed
- B. The model only needs to be loaded once per executor rather than once per batch during the inference process
- C. The data will be limited to a single executor preventing the model from being loaded multiple times
- D. The data will be distributed across multiple executors during the inference process
Answer: B
Explanation:
Using an iterator in the pandas_udf ensures that the model only needs to be loaded once per executor rather than once per batch. This approach reduces the overhead associated with repeatedly loading the model during the inference process, leading to more efficient and faster predictions. The data will be distributed across multiple executors, but each executor will load the model only once, optimizing the inference process.
Reference:
Databricks documentation on pandas UDFs: Pandas UDFs
NEW QUESTION # 44
A data scientist has defined a Pandas UDF function predict to parallelize the inference process for a single-node model:
They have written the following incomplete code block to use predict to score each record of Spark DataFrame spark_df:
Which of the following lines of code can be used to complete the code block to successfully complete the task?
- A. mapInPandas(predict(spark_df.columns))
- B. predict(*spark_df.columns)
- C. predict(spark_df.columns)
- D. predict(Iterator(spark_df))
- E. mapInPandas(predict)
Answer: E
Explanation:
To apply the Pandas UDF predict to each record of a Spark DataFrame, you use the mapInPandas method. This method allows the Pandas UDF to operate on partitions of the DataFrame as pandas DataFrames, applying the specified function (predict in this case) to each partition. The correct code completion to execute this is simply mapInPandas(predict), which specifies the UDF to use without additional arguments or incorrect function calls.
Reference:
PySpark DataFrame documentation (Using mapInPandas with UDFs).
NEW QUESTION # 45
A data scientist is using MLflow to track their machine learning experiment. As a part of each of their MLflow runs, they are performing hyperparameter tuning. The data scientist would like to have one parent run for the tuning process with a child run for each unique combination of hyperparameter values. All parent and child runs are being manually started with mlflow.start_run.
Which of the following approaches can the data scientist use to accomplish this MLflow run organization?
- A. They can specify nested=True when starting the child run for each unique combination of hyperparameter values
- B. They can start each child run with the same experiment ID as the parent run
- C. They can start each child run inside the parent run's indented code block using mlflow.start runO
- D. They can specify nested=True when starting the parent run for the tuning process
- E. They can turn on Databricks Autologging
Answer: A
Explanation:
To organize MLflow runs with one parent run for the tuning process and a child run for each unique combination of hyperparameter values, the data scientist can specify nested=True when starting the child run. This approach ensures that each child run is properly nested under the parent run, maintaining a clear hierarchical structure for the experiment. This nesting helps in tracking and comparing different hyperparameter combinations within the same tuning process.
Reference:
MLflow Documentation (Managing Nested Runs).
NEW QUESTION # 46
A data scientist is using the following code block to tune hyperparameters for a machine learning model:
Which change can they make the above code block to improve the likelihood of a more accurate model?
- A. Change sparkTrials() to Trials()
- B. Increase num_evals to 100
- C. Change tpe.suggest to random.suggest
- D. Change fmin() to fmax()
Answer: B
Explanation:
To improve the likelihood of a more accurate model, the data scientist can increase num_evals to 100. Increasing the number of evaluations allows the hyperparameter tuning process to explore a larger search space and evaluate more combinations of hyperparameters, which increases the chance of finding a more optimal set of hyperparameters for the model.
Reference:
Databricks documentation on hyperparameter tuning: Hyperparameter Tuning
NEW QUESTION # 47
Which of the following describes the relationship between native Spark DataFrames and pandas API on Spark DataFrames?
- A. pandas API on Spark DataFrames are unrelated to Spark DataFrames
- B. pandas API on Spark DataFrames are more performant than Spark DataFrames
- C. pandas API on Spark DataFrames are made up of Spark DataFrames and additional metadata
- D. pandas API on Spark DataFrames are single-node versions of Spark DataFrames with additional metadata
- E. pandas API on Spark DataFrames are less mutable versions of Spark DataFrames
Answer: C
Explanation:
Pandas API on Spark (previously known as Koalas) provides a pandas-like API on top of Apache Spark. It allows users to perform pandas operations on large datasets using Spark's distributed compute capabilities. Internally, it uses Spark DataFrames and adds metadata that facilitates handling operations in a pandas-like manner, ensuring compatibility and leveraging Spark's performance and scalability.
Reference
pandas API on Spark documentation: https://spark.apache.org/docs/latest/api/python/user_guide/pandas_on_spark/index.html
NEW QUESTION # 48
Which of the Spark operations can be used to randomly split a Spark DataFrame into a training DataFrame and a test DataFrame for downstream use?
- A. DataFrame.where
- B. DataFrame.randomSplit
- C. TrainValidationSplit
- D. TrainValidationSplitModel
- E. CrossValidator
Answer: B
Explanation:
The correct method to randomly split a Spark DataFrame into training and test sets is by using the randomSplit method. This method allows you to specify the proportions for the split as a list of weights and returns multiple DataFrames according to those weights. This is directly intended for splitting DataFrames randomly and is the appropriate choice for preparing data for training and testing in machine learning workflows.
Reference:
Apache Spark DataFrame API documentation (DataFrame Operations: randomSplit).
NEW QUESTION # 49
......
Get Ready with Databricks-Machine-Learning-Associate Exam Dumps (2024): https://actual4test.torrentvce.com/Databricks-Machine-Learning-Associate-valid-vce-collection.html